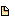|
|
File #1
x MA
y FL
z UT
File #2
x
y
u
w
Output
x MA
y FL
File1 & File2 are very huge datasets. Please advise! Thank you
|
|
|
|
u take each file and put it into as hash.
then u have two hashes, u go through the keys of the former hash,
find that very key in the latter hash, and add it to the former hash.
when that is done the former hash represents both hashes,
u then put that hash into a new file.
|
|
|
|
you could put each file in a hash but that way would be a lot slower and most people that would write that script would use an array.
basically you want to match data from 2 files and make a new file/list with the matched data.
#!perl
use strict;
use warnings;
use Fcntl qw(:DEFAULT :flock);
# Full path to each file and must have file name
my $file = ''; #1
my $file2 = ''; #2
my $output = ''; #Output
my @content = ();
sysopen(FH, $file, O_RDONLY);
flock(FH, LOCK_EX);
@content = <FH>;
close(FH);
my @content2 = ();
sysopen(FH, $file2, O_RDONLY);
flock(FH, LOCK_EX);
@content2 = <FH>;
close(FH);
my @Output = ();
foreach (@content) {
my ($letter, $state) = split(/\s/, $_);
foreach (@content2) {
push(@Output, join(" ", $letter, $state)) if $letter eq $_;
}
}
print "@Output";
Please make Back-ups of the files you are using.
|
|
|
|
my thought on the hashes is that they have a seek time of one.
and since we're looking for every instance of former array, through every instance of latter array,
the big-o time should be to the second power.
whereas using hashes it should be to the first power because for every instance in former array, we seek that exact element with a seek time of 1.
thats because we already know the key of the hash, we dont have to wade through anything.
meaning hashes should be faster.
i worry about the memory usage though, in both solutions.
|
|
|
|
my thought on the hashes is that they have a seek time of one.
and since we're looking for every instance of former array, through every instance of latter array,
the big-o time should be to the second power.
whereas using hashes it should be to the first power because for every instance in former array, we seek that exact element with a seek time of 1.
thats because we already know the key of the hash, we dont have to wade through anything.
meaning hashes should be faster.
i worry about the memory usage though, in both solutions. |
|
Im sorry but what you said makes no sense to me. maybe if you produce a code to help me understand what you mean.
as for memory usage, you should have nothing to worry about unless both files are 1gb+ or the system doing the task is low on resources.
|
|
|
|
the array solution:
by using arrays we have to go through the first array, and for each element in that array,
walk through the second array asking if thats the element matching the one in the former array we're looking for.
double the size of the arrays and we're gonna be having:
-twice as many elements to check,
-twice as many elements to wade through for each.
so when the lists double in size, the strain on the cpu quadruples.
10 fold the lists and we'll have a 10*10 larger strain on the cpu.
it's what can be called a 'big-o second power' solution.
the hash solution:
by using hashes we go through the first hash, and for each value in it, we pick the corresponding key in the latter up and do our stuff. hashes have an access time of one so we dont have to wade through anything for we already know exactly where it is to be found.
so if the files double in size, the strain on the cpu will double.
if the files quadruple in size, the strain on the cpu will quadruple.
it's what can be called a 'big-o first power' solution.
big-o is basically a measure of scalability.
|
|
|
|
I believe you are over thinking the task.
this post is on merging 2 files not optimizing the merger of 2 files.
What you say could be true, but you have not given a workable example to reinforce your claims.
|
|
|
|
true, i only felt like giving a pseudo code solution.
|
|
|
|
Thank you very much.
Hash is a great idea.
I am a new PERL user ( 2 days old : ) ), a little big hard to write the real stuff. I will study more about Hash syntax.
Thank you again!!!
|
|
|
|
I do not know what to say.
You saved my life :) I've been upset since last night.
Thank you so much!!
|
|
|
|
|
|
|
// |


 pangpang
pangpang